

AI and ML developers often work with local datasets in data pre-processing. Technical features and prototyping make this easy without the overhead of an entire server. The most common comparison is between SQLite, a serverless database released in 2000 and widely used for lightweight transactions, and DuckDB, introduced in 2019 as the SQLite of analytics, focused on fast, in-process analytics queries. While both are built in, their goals are different. In this article, we compare DuckDB and SQLite to help you choose the right tool for each stage of your AI workflow.
What is SQLite?
SQLite is a standalone database engine that is serverless. Creates a button directly from a file on disk. It has zero configuration and has a low footprint. The entire database is stored in one is.sqlite file, and all tables and indexes are contained in this file. The engine itself is a C library that is built into your application.
SQLite is an ACID-compliant database, albeit a simple one. This makes it dependent on transactions and data integrity.
Key features include:
- Row-oriented storage: Data is stored row by row. This makes updating or retrieving a single row quite efficient.
- Single file database: The entire database is in one file. This allows it to be easily copied or transferred.
- No server processes: Direct reading and writing to the database file is done in your application. No separate server is needed.
- Extensive SQL support: It is based on most of SQL-2 and supports such things as joins, window functions, and indexes.
SQLite is often chosen in mobile applications and the Internet of Things, as well as in small web applications. It shines where you require a straightforward solution for local storage of structured data and when you will require numerous short read and write operations.
What is DuckDB?
DuckDB is a database for in-process data analysis. Built-in applications require the power of a SQL database. It will perform complex serverless analytical queries efficiently. This analytical focus is often the basis of comparisons between DuckDB and SQLite.
Important features of DuckDB are:
- Columnar storage format: DuckDB stores data columns. In this format, it is able to scan and merge huge data sets much faster. It only reads the columns it requires.
- Vectorized query execution: DuckDB is designed to perform calculations in blocks or vectors, rather than in a single line. This method involves using the current capabilities of the CPU to compute at a higher speed.
- Querying the file directly: DuckDB can query Parquet, CSV and Arrow files directly. It is not necessary to insert them into the database.
- Deep data science integration: It is compatible with Pandas, NumPy and R. DataFrames can be queried like database tables.
DuckDB can be used to quickly process interactive data analysis in Jupyter notebooks and accelerate Pandas workflows. It requires data warehouse capabilities in a small and local package.
Key differences
First, here is a summary table comparing SQLite and DuckDB in important aspects.
| Appearance | SQLite (since 2000) | DuckDB (as of 2019) |
| Primary purpose | Built-in OLTP database (transactional) | Built-in OLAP database (analytics) |
| Storage model | Based on rows (glues whole rows together) | Columnar (blind columns together) |
| Query execution | Iterative processing by rows | Vectorized batch processing |
| Performance | Excellent for small, frequent transactions | Excellent for big data analytics queries |
| Data size | Optimized for small to medium datasets | Handles large and out-of-memory datasets |
| Competition | Multi-reader, one writer (via locks) | Multi-reader, single-writer; parallel query execution |
| Memory usage | Minimum memory requirements by default | It uses memory for speed; can use more RAM |
| SQL properties | Robust basic SQL with some limits | Extensive SQL support for advanced analysis |
| Indexes | B-tree indexes are often needed | It relies on column scanning; indexing is less common |
| Integration | Supported in almost all languages | Native integration with Pandas, Arrow, NumPy |
| File formats | Proprietaryfile; can import/export CSV files | Can query Parquet, CSV, JSON, Arrow directly |
| Transaction | Fully compatible with ACID | ACID within a single process |
| Parallelism | Single-threaded query execution | Multi-threaded execution for a single query |
| Typical use cases | Mobile apps, IoT devices, local app storage | Data science notebooks, local ML experiments |
| License | Public domain | MIT License (open source) |
This table shows that SQLite focuses on reliability and transaction operations. DuckDB is optimized to support fast analytical queries on big data. We will now discuss each of them.
Practical Python: From Theory to Practice
We will see how to use both databases in Python. It is an open-source AI development environment.
Using SQLite
This is Python’s easy representation of SQLite. We create a table, enter data and execute a query.
import sqlite3
# Connect to a SQLite database file
conn = sqlite3.connect("example.db")
cur = conn.cursor()
# Create a table
cur.execute(
"""
CREATE TABLE users (
id INTEGER PRIMARY KEY,
name TEXT,
age INTEGER
);
"""
)
# Insert records into the table
cur.execute(
"INSERT INTO users (name, age) VALUES (?, ?);",
("Alice", 30)
)
cur.execute(
"INSERT INTO users (name, age) VALUES (?, ?);",
("Bob", 35)
)
conn.commit()
# Query the table
for row in cur.execute(
"SELECT name, age FROM users WHERE age > 30;"
):
print(row)
# Expected output: ('Bob', 35)
conn.close()exit:
In this case, the database is stored in example.db file. We created a table, added two rows to it, and ran a simple query. SQLite allows you to load data into tables and then query them. In case you have a CSV file, you need to import the information first.
Using DuckDB
Still, it’s time to revisit this option with DuckDB. We’ll also highlight its data science capabilities.
import duckdb
import pandas as pd
# Connect to an in-memory DuckDB database
conn = duckdb.connect()
# Create a table and insert data
conn.execute(
"""
CREATE TABLE users (
id INTEGER,
name VARCHAR,
age INTEGER
);
"""
)
conn.execute(
"INSERT INTO users VALUES (1, 'Alice', 30), (2, 'Bob', 35);"
)
# Run a query on the table
result = conn.execute(
"SELECT name, age FROM users WHERE age > 30;"
).fetchall()
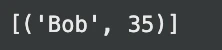
print(result) # Expected output: (('Bob', 35))exit:
Simple use is similar to basic use. However, external data can also be queried by DuckDB.
Let’s generate a random dataset for querying:
import pandas as pd
import numpy as np
# Generate random sales data
np.random.seed(42)
num_entries = 1000
data = {
"category": np.random.choice(
("Electronics", "Clothing", "Home Goods", "Books"),
num_entries
),
"price": np.round(
np.random.uniform(10, 500, num_entries),
2
),
"region": np.random.choice(
("EUROPE", "AMERICA", "ASIA"),
num_entries
),
"sales_date": (
pd.to_datetime("2023-01-01")
+ pd.to_timedelta(
np.random.randint(0, 365, num_entries),
unit="D"
)
)
}
sales_df = pd.DataFrame(data)
# Save to sales_data.csv
sales_df.to_csv("sales_data.csv", index=False)
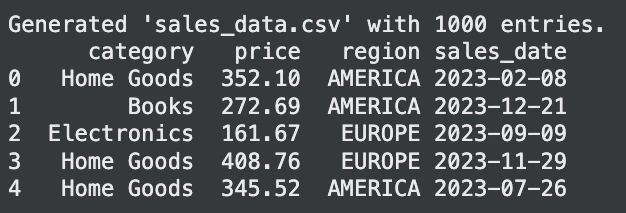
print("Generated 'sales_data.csv' with 1000 entries.")
print(sales_df.head())exit:
Now let’s query this table:
# Assume 'sales_data.csv' exists
# Example 1: Querying a CSV file directly
avg_prices = conn.execute(
"""
SELECT
category,
AVG(price) AS avg_price
FROM 'sales_data.csv'
WHERE region = 'EUROPE'
GROUP BY category;
"""
).fetchdf() # Returns a Pandas DataFrame
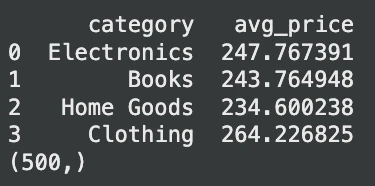
print(avg_prices.head())
# Example 2: Querying a Pandas DataFrame directly
df = pd.DataFrame({
"id": range(1000),
"value": range(1000)
})
result = conn.execute(
"SELECT COUNT(*) FROM df WHERE value % 2 = 0;"
).fetchone()
print(result) # Expected output: (500,)exit:
In this case, DuckDB reads the CSV file on the fly. No important step is required. It is also capable of querying a Pandas DataFrame. This flexibility removes much of the data loading code and simplifies AI pipelines.
Architecture: Why they work so differently
The performance differences between SQLite and DuckDB have to do with their storage and query engines.
- Storage model: SQLite is row based. It groups together all the data of one row. This is very good for updating a single record. However, it is not fast with analytics. Assuming you only need one column, then SQLite will have to read all the data for each row. DuckDB is column oriented. Puts all the values of one column into one column. This is ideal for analysis. A query such as
SELECT AVG(age)it only reads age column, which is much faster. - Query execution: SQLite one query per row. This is memory efficient when it comes to small queries. DuckDB is based on a vectorized implementation. Works with large batch data. This technique uses current CPUs to significantly speed up large scans and joins. It is also capable of running many threads to execute a single query at a time.
- Memory and disk behavior: SQLite is designed to use minimal memory. Reads from disk as needed. DuckDB uses memory to increase speed. It can execute data larger than available RAM during out-of-kernel execution. This means that DuckDB may consume more RAM, but it is much faster in the analysis task. Aggregation queries have been shown to be 10-100 times faster in DuckDB than in SQLite.
Verdict: When to use DuckDB vs. DuckDB SQLite
This is a good guideline to follow in your AI and machine learning projects.
| Appearance | Use SQLite when | Use DuckDB when |
|---|---|---|
| Primary purpose | You need a lightweight transactional database | You need fast local analysis |
| Data size | Low data volume, up to several hundred MB | Medium to large datasets |
| Workload type | Insert, update and simple search | Aggregate, join and scan large tables |
| Transaction needs | Frequent small updates with transactional integrity | Analytical questions that are difficult to read |
| File manipulation | Data stored in a database | Query CSV or Parquet files directly |
| Focus on performance | Minimal footprint and simplicity | High-speed analytical performance |
| Integration | Mobile applications, embedded systems, IoT | Pandas-based parsing acceleration |
| Parallel design | Not a priority | Uses multiple CPU cores |
| A typical use case | Application state and lightweight storage | Local research and data analysis |
Conclusion
Both SQLite and DuckDB are powerful embedded databases. SQLite is a very good lightweight data store and easy transaction tool. However, DuckDB can significantly speed up data processing and AI prototyping by big data developers. This is because when you realize their differences, you will know the right tool to use in different tasks. In the case of simultaneous data analysis and machine learning processes, DuckDB can save you a lot of time with a significant performance benefit.
Frequently Asked Questions
Answer: No, they have other uses. DuckDB is used for quick analysis (OLAP) access, while SQLite is used to enter reliable transactions. Choose according to your workload.
Answer: SQLite is usually better suited for web applications that have a large number of small communicating reads and writes because it has a reliable transaction model and WAL mode.
Answer: Yes, for most large tasks like group-bys and joins, DuckDB can be much faster than Pandas due to its parallel vectorized engine.
![]()
Harsh Mishra is an AI/ML engineer who spends more time talking to large language models than real people. Passionate about GenAI, NLP and making machines smarter (so they’re not replacing him yet). When he’s not optimizing models, he’s probably optimizing coffee intake. 🚀☕
Sign in to continue reading and enjoy content created by experts.